Natural Language Processing
To view the complete code of the NLP : click here
Natural language processing (NLP) is the ability of a computer program to understand human language as it is spoken and written -- referred to as natural language. It is a component of artificial intelligence (AI). NLP has existed for more than 50 years and has roots in the field of linguistics. It has a variety of real-world applications in a number of fields, including medical research, search engines and business intelligence.
NLP enables computers to understand natural language as humans do. Whether the language is spoken or written, natural language processing uses artificial intelligence to take real-world input, process it, and make sense of it in a way a computer can understand. Just as humans have different sensors -- such as ears to hear and eyes to see -- computers have programs to read and microphones to collect audio. And just as humans have a brain to process that input, computers have a program to process their respective inputs. At some point in processing, the input is converted to code that the computer can understand.

Analysis Report
In the Executive Summary, the nlp thought process was summarized in a non-technical format. In this section, the technical aspects are explained in a detailed fashion: the steps taken and the reasoning behind every decision. As mentioned in the Summary, this subreddit consists of 18million+ rows so the concepts of big data are applied to leverage the data. The data for this analysis is picked up from the last transformation performed in eda.
Before cleaning the dataset, we start with the basic data text checks. First we found the most common words in general. After looking at the output, it is evident that cleaning is required as stopwords cannot be the top 10 words with highest count.
Next question that we tried to answer was to find the distribution of text lengths. It was observed that some of the texts with the higher comment length are not useful for analysis (deleted etc). These words/sentences can be removed later.
We created Pandemic_Freakout and Arrest_Freakout as the two new dummy variables to help with our analysis. We identify the important keywords pertaining to the dummy variable and used regex searches to identify comments of particular topics. For Pandemic_Freakout terms such as "covid", "mask", "corona", "virus" were searched and for Arrest_Freakout sentences containing "officer", "illegal", "police", "stab" were searched.
Cleaning the data
This next step is the most important step when dealing with text data. A pipeline is created to clean the text. Different stages such as documentAssembler, tokenizer, normalizer, lemmatizer, stopwords_cleaner, finisher are ordered in the pipeline.
After applying the cleaning pipeline, sentiment analysis model is applied. jonsnowlabs sparkNLP is used to pick up the pipeline/models. Again a pipelne is created to find the sentiments. DocumentAssembler, UniversalSentenceEncoder and sentimentdl_use_twitter from Jonsnow labs is ordered in a pipeline. Only the columns that are required are selected from the dataframe and the new dataframe is stored in s3.
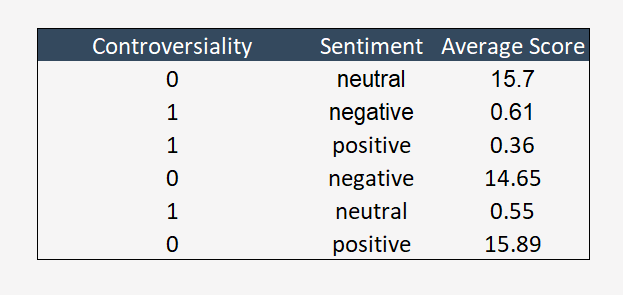
Moving on, the first business question that is tried to answer is the total sentiment count of comments throughout our timeframe. Through this we can identify the ditribution of the sentiments of the comments. There are very few comments overall having neutral sentiment compared to the other two sentiments. Majority of the comments have a positive sentiment, this might be the case as the authors might leave motivational or happy comments under freakout videos or else there are comparatively more video under happy freakout category.
Moving on, in the previous graph since we found out the total count in the sentiments, we can deep dive into the count of the sentiments through time. In this next plot, we try to look at the Relationship between Time Period and Frequency of Comments for each Sentiment. It can be seen that there is not much change in the neutral sentiment throughout the timeframe. The fluctuations of count for positive and negative sentiment is similar. Both the sentiments have a spike in their count around the time when covid hit (March 2020).
Now we have sentiment of authors through each comment revolving around the terms of covid. The dummy variable Pandemic_Freakout is used which is created by using regex and extracting all the keywords. A new flag is created is_pandemic_freakout, 1 where the keyword is detected and 0 where it is empty. This plot contains the number of comments for every sentiment split by the pandemic freakout flag. It can be seen that very few comments have public freakout flag irrespective of the sentiment. It makes sense as the covid high or the covid discussion died down after a few months.
Now we have sentiment of authors through each comment revolving around the terms of covid. The dummy variable Arrest_Freakout is used which is created by using regex and extracting all the keywords. A new flag is created is_arrest_freakout, 1 where the keyword is detected and 0 where it is empty. This plot contains the number of comments for every sentiment split by the pandemic freakout flag. It can be seen that very few comments have public freakout flag irrespective of the sentiment. It makes sense as the covid high or the covid discussion died down after a few months.
Reference : Tech Target